- Published on
The CAP Theorem
- Authors

- Name
- tomiwa
- @sannimichaelse
What is the CAP Theorem?
The CAP Theorem is a fundamental theorem in distributed systems that states that any distributed system can have at most two of the following three properties.
- Consistency
- Availability
- Partition tolerance
What does this mean
A Distributed System
Let's consider a very simple distributed system. Our system is composed of a cluster with two nodes. N1 and N2 Both of these nodes are keeping track of the same variable,v whose value is initially v0. N1 and N2 can communicate with each other and can also communicate with external clients. Here's what our system looks like.
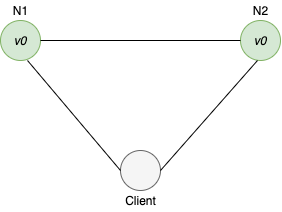
A client can request to write and read from any node. When a node receives a request, it performs any computations it wants and then responds to the client. For example, here is what a write looks like.
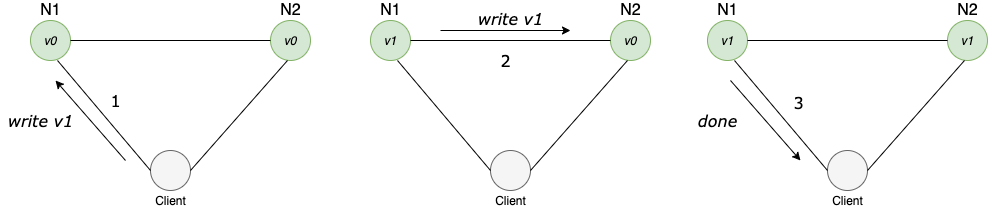
In the diagram above the client requests a write on node1 and because node2 is not aware of the new changes, node1 also writes to node2 before returning a response to the client
And here is what a read looks like.
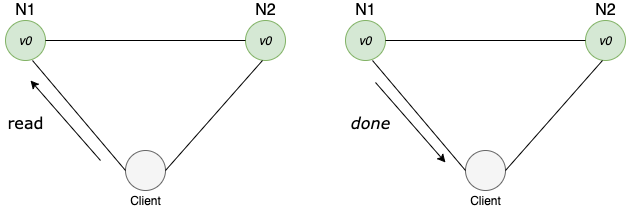
Because node1 and node2 have the same state the response is returned immediately on read operation.
Now that we've gotten our system established, let's go over what it means for the system to be consistent, available, and partition tolerant.
Consistency
In a consistent system, once a client writes a value to any node and gets a response, it expects to get that value (or a fresher value) back from any node it reads from.
There is an edge case about consistency, Some systems usually sacrifice availability for consistency due to network partitioning. We will talk more about this when proving the law
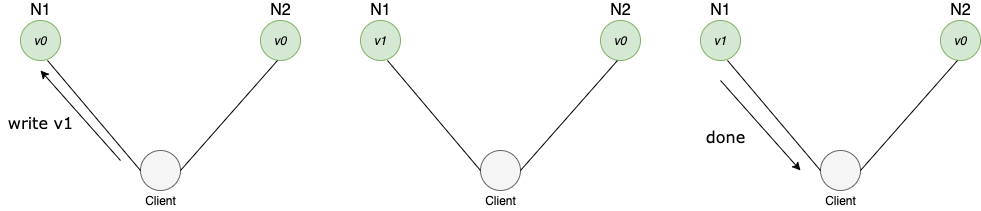
a system in an inconsistent state
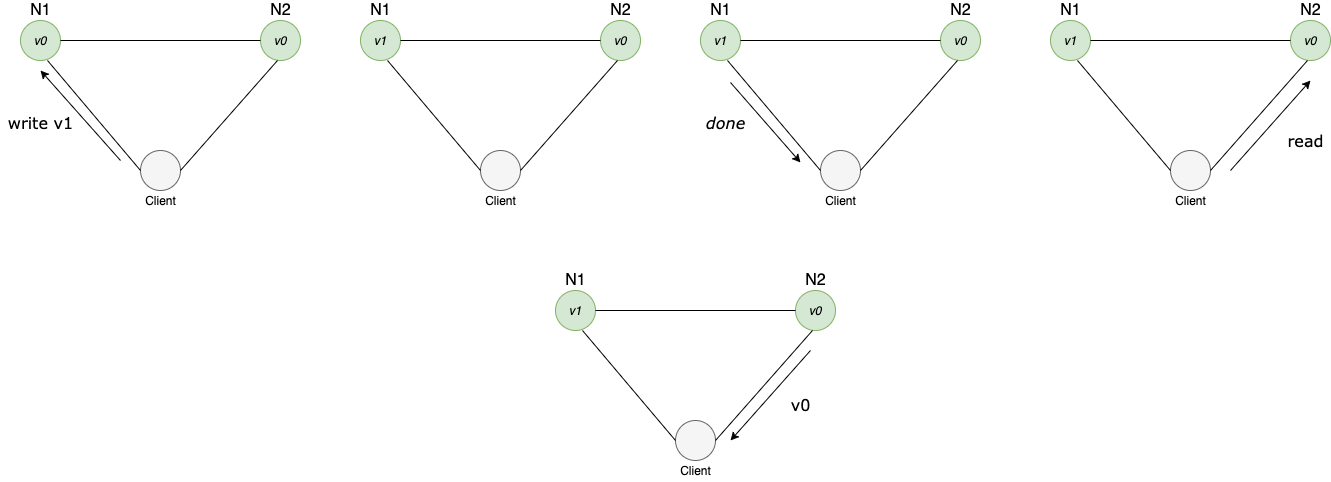
In this system, the first node acknowledges the data without replicating it to the second node. When the client tries to pull data from node2 the client will be getting stale data.
a system in a consistent state
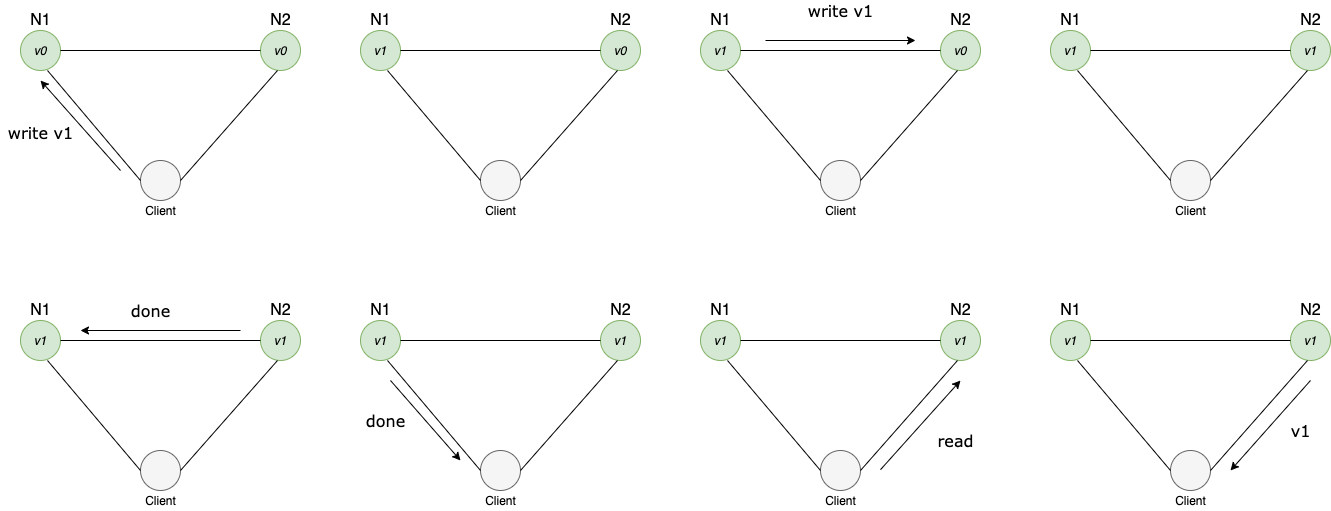
In the system above, the first node acknowledges the data and replicates it to the second node before responding to the client. So the client will always have access to the updated data when pulling from node2.
NB The replication across nodes in a cluster usually happens in a matter of milliseconds, so the client might not even be aware of what's going on
Availability
Availability means the ability to access the cluster even if a node in the cluster goes down. Achieving availability in a distributed system requires that the system remains operational 100% of the time. Every client gets a response, regardless of the state of any individual node in the system.
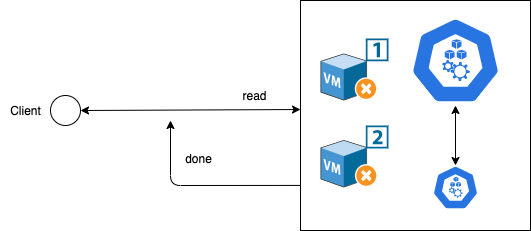
In the diagram above, we can see that two nodes are down, see a node like a system, it can be a physical server or a virtual machine. The master node will still be able to communicate with the worker nodes and return appropriate responses to the client. So the system is highly available. High availability and fault-tolerance are parts of the core strengths of distributed systems
Partition Tolerance
Partition tolerance means that the cluster continues to function even if there is a partition (communication break) between two nodes (both nodes are up, but can't communicate). The network will be allowed to lose arbitrarily many messages sent from one node to another. This means that any messages N1 and N2 send to one another can be dropped. If all the messages were being dropped, then our system would look like this.
Our system has to be able to function correctly despite arbitrary network partitions in order to be partition tolerant. It means that despite the partition or lack of communication between nodes that are up and running, the system should still be able to respond to requests
Proving the CAP Theorem
Assume for contradiction that there does exist a system that is consistent, available, and partition tolerant. The first thing we do is partition our system. It looks like this.
Next, we have the client requests a write operation to node1, this is what our system will look like
In the diagram above, the client requests a write to node1, because the system is partitioned, node1 cannot replicate the data to node2 so it means the data will not be consistent. node1 will have to respond to the client which makes it highly available
Here we have our first combination mapped out. The system has two features here
- Highly available - A
- Partition Tolerant- P
AP or PA
Let's look at the next combination
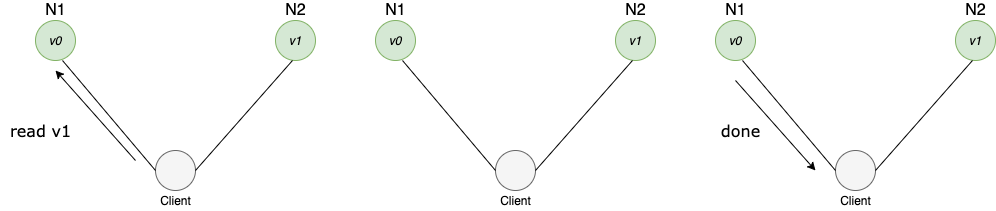
In the diagram above, the client requests a read operation from node1 after the systems were partitioned. Though node1 was able to return a response that makes it consistent, the data we need which is v1 is not available. Some systems usually return an error or a message if the actual data the client is looking for is not available at the moment. Remember that this category refers to the group of systems that sacrifice availability for consistency
At first glance, the CP category is confusing, i.e., a system that is consistent and partition tolerant but never available. CP is referring to a category of systems where availability is sacrificed only in the case of a network partition - Dzone
Here we have our new combination
- Consistent C
- Partition tolerant P
CP or PC
Looking at the final combination
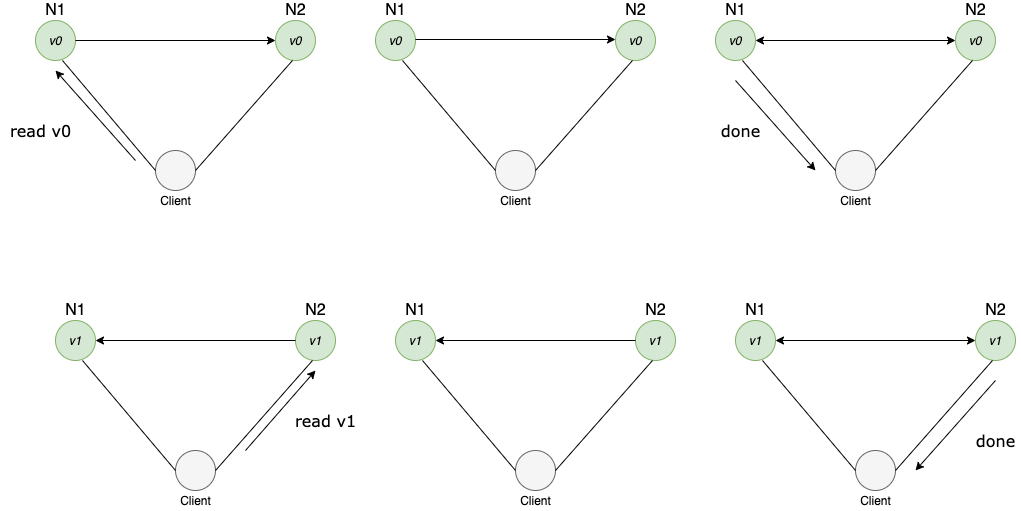
In the diagram above, the system is both Consistent and Highly Available
CA or AC
No distributed system is safe from network failures, thus network partitioning generally has to be tolerated. In the presence of a partition, one is then left with two options: consistency or availability. When choosing consistency over availability, the system will return an error or a time out if particular information cannot be guaranteed to be up to date due to network partitioning. When choosing availability over consistency, the system will always process the query and try to return the most recent available version of the information, even if it cannot guarantee it is up to date due to network partitioning In the absence of network failure – that is, when the distributed system is running normally – both availability and consistency can be satisfied - Wikipedia
Conclusion
Distributed systems allow us to achieve a level of computing power and availability that were simply not available in the past. Our systems have higher performance, lower latency, and near 100% up-time in data centers that span the entire globe. Best of all, the systems of today are run on commodity hardware that is easily obtainable and configurable at affordable costs. However, there is a price. Distributed systems are more complex than their single-network counterparts. Understanding the complexity incurred in distributed systems, making the appropriate trade-offs for the task at hand (CAP), and selecting the right tool for the job is necessary