- Published on
Data Consistency Levels in Distributed Systems
- Authors

- Name
- tomiwa
- @sannimichaelse
Introduction
Data consistency in distributed systems refers to the requirement that all copies of a piece of data must be kept in a consistent state, meaning they must all be updated or accessed uniformly. Maintaining data consistency is important in distributed systems because it ensures that all users see a consistent view of the data, regardless of which copy they are accessing.
Consistency Levels
Several different levels of data consistency can be achieved in a distributed system:
Strong/strict consistency
With strong consistency, all reads from the system will return the most recently written value. This means that if a user writes a new value to the system, this value will be instantly available to any other process in the system. Strong consistency guarantees that all users will see the same value when reading from the system. You can see it as a global clock, and if there was a
Write(x, 1) at Time t1,
Then any
Read(x) will return a newly written value 1 at any instant t2 > t1.
Linearizability
Linearizability is a stronger form of consistency than strong consistency. In a linearizable system, all reads and writes appear to occur in a single atomic operation. This means that if a user writes a new value to the system, all subsequent reads from that user will return the new value. The operations are performed as if on a single machine despite the distribution of data across multiple nodes. So reads after a write operation will return the newly written value.
Example of Linearizability
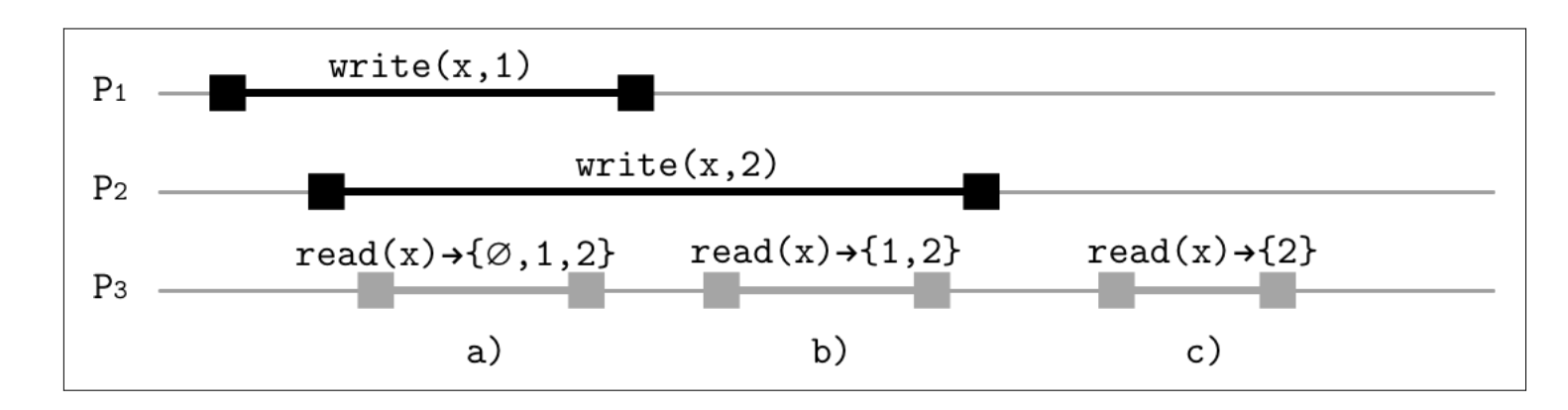
Given three processes P1, P2 and P3
| Process 1 | Process 2 | Process 3 |
|---|---|---|
| write(x, 1) | write(x, 2) | read(x) |
| read(x) | ||
| read(x) |
a) The first read operation can return 1, 2, or ∅ (the initial value, a state before both writes) since both writes are still in-flight. The first read can be ordered before both writes, between the first and second writes, and after both.
b) The second read operation can return only 1 and 2 since the first write has been completed, but the second write hasn’t returned.
c) The third read can only return 2 since the second write is ordered after the first.
Sequential consistency
Sequential consistency guarantees that all reads and writes will appear in the order in which they were issued. This means that if a user writes a new value to the system, all subsequent reads from that user will return the new value
Example
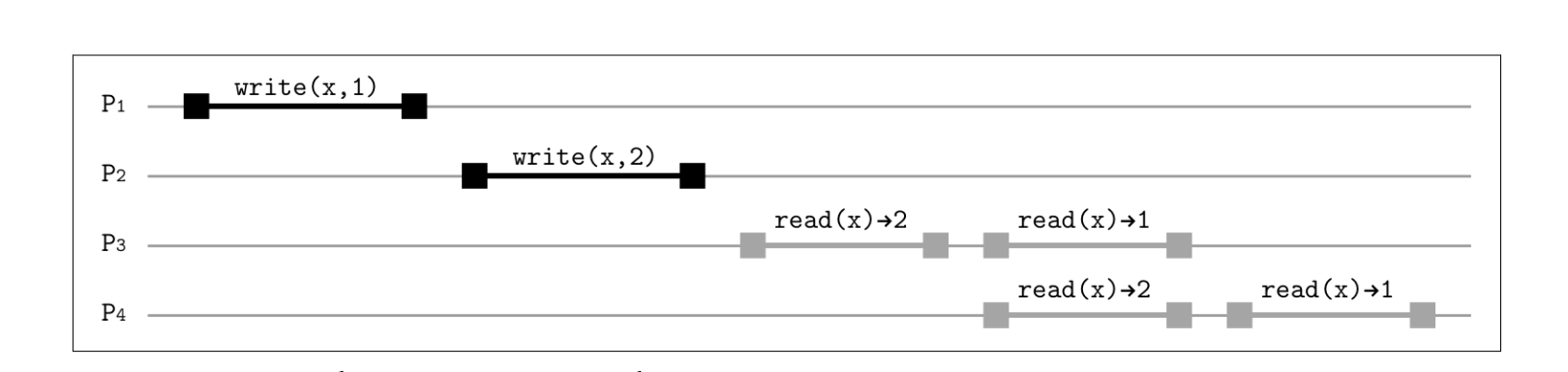
Given four processes P1, P2, P3, P4
write(x,1) and write(x,2) in the first and second processes can become visible to P3 and P4. Even though in wall-clock terms, 1 was written before 2, it can get ordered after 2. At the same time, while P3 already reads the value 1, P4 can still read 2. However, both orders, 1 → 2 and 2 → 1 are valid as long as they’re consistent for different readers. What’s important here is that both P3 and P4 have observed values in the same order: first 2, and then 1
Causal consistency
Causal consistency guarantees that if two operations are related in some way, they will be seen by all users in the same order. For example, if a user writes a new value to the system and then reads the value back, the read operation will always return the new value. Under the causal consistency model, all processes must see causally related operations in the same order.
For example

P1 starts with a write operation write(x,∅,1)→t1, which starts from the initial value ∅. P2 performs another write operation, write(x, t1, 2), and specifies that it is logically ordered after t1, requiring operations to propagate only in the order established by the logical clock. This establishes a causal order between these operations
Eventual consistency
Eventual consistency is the weakest form of consistency. In an eventually consistent system, different users can see different versions of the data at different times. Eventually, consistent systems do not guarantee that all users will see the same data, but they guarantee that all users will see the same data.
Quorum-based consistency
It involves using a "quorum" of nodes, or a minimum number of nodes, to ensure that a particular operation has been completed before it is considered successful. For example, a quorum of two nodes could be established in a distributed system with three nodes. This means that for a write operation to be considered successful, it must be written to at least two of the three nodes. Similarly, for a read operation to be successful, it must be read from at least two of the three nodes. It is often used in distributed systems to balance strong consistency and availability. By requiring a quorum of nodes to participate in an operation, the system can ensure that data is consistent across multiple nodes while still allowing the system to continue functioning even if one or more nodes are unavailable.
Choosing the Right Consistency Level
When designing a distributed system, carefully considering the desired level of data consistency is essential. Different consistency levels come with different trade-offs in terms of availability and performance. More robust consistency levels, such as linearizability and strong consistency, offer more guarantees about the system's behavior but may result in a reduced availability or slower performance. Weaker consistency levels, such as eventual consistency, offer fewer guarantees but may result in higher availability and better performance.
When choosing the right consistency level for a distributed system, there are several factors to consider:
Use case: Different use cases may require different levels of consistency. For example, a real-time trading platform may require strong consistency to ensure that all users see the most up-to-date prices. In contrast, a social media platform may be able to tolerate eventual consistency for certain types of data.
Architecture: The architecture of a distributed system can also influence the appropriate consistency level. For example, systems with multiple copies of data may tolerate weaker consistency levels, while systems with a single copy of data may require stronger consistency.
Level of availability: As mentioned above, stronger consistency levels may result in reduced availability, while weaker consistency levels may result in higher availability. It is essential to consider the desired level of availability when choosing a consistency level.
Consistency Levels in Practice
Strong consistency: Google Docs is an example of a system that uses strong consistency. In Google Docs, multiple users can edit the same document simultaneously, and the system ensures that all users see the most up-to-date version of the document at all times.
Linearizability: The Bitcoin blockchain is an example of a system that uses linearizability. The blockchain is a distributed ledger that records all Bitcoin transactions, and all users must always see the exact version of the ledger. To achieve this, the blockchain uses linearizability to ensure that all transactions are processed in a single atomic operation.
Sequential consistency: Memcached is an example of a system that uses sequential consistency. Memcached is a distributed in-memory cache that is used to store frequently accessed data to improve the performance of web applications. In Memcached, all reads and writes are guaranteed to occur in the order in which they were issued.
Causal consistency: Google Cloud Firestore is an example of a system that uses causal consistency. Firestore is a NoSQL document database designed for real-time web and mobile applications. In Firestore, all writes to the database are guaranteed to be causally related. If a user writes a new value to the database and then reads it back, the read operation will always return the new value.
Eventual consistency: Amazon DynamoDB is an example of a system that uses eventual consistency. DynamoDB is a NoSQL key-value store designed for high scalability and availability. In DynamoDB, different users can see different versions of the data at different times, but the system guarantees that, eventually, all users will see the same data.
Conclusion
In this article, you have learned about the different data consistency levels that can be achieved in distributed systems, including strong consistency, linearizability, sequential consistency, causal consistency, and eventual consistency. You also learned about the trade-offs in choosing a consistency level with examples of how the levels are used in practice. It is essential to carefully consider the desired level of consistency when designing a distributed system, as the chosen level can significantly impact the system's behavior and performance.