- Published on
An Introduction to Kafka
- Authors

- Name
- tomiwa
- @sannimichaelse
Introduction
For a long time now, we've always kept data in the database and they made us think in terms of objects(things). These objects(things) usually have attributes like name, color, weight, etc. In today's world keeping track of data has grown to be very dynamic, we don't want to only know about the objects(things) but we also want to know what is happening to them at each point in time. This is where events come in. It would not make sense to store events in the database because a lot of events could have happened within a period of time e.g button click. What if we have a distributed system that helps keep tracks of the constant influx of data and allows us to think in terms of events as opposed to thinking in terms of objects and their attributes as well as provides results in real-time? This is where Apache Kafka comes in.
What is Apache Kafka
Apache Kafka is a distributed data store that is used for ingesting and processing streaming data in real-time. It was built to handle the constant influx of data and process the data sequentially.
Why Kafka
I was recently working on a project where we needed to stream real-time transactions from a platform. It happened the client already had a Kafka broker setup and they act as the producer - pushing events to one or more consumers. Our task was to act as a consumer and pull transactions in real-time whenever there is a message in the queue. It sounded very interesting and I tried to read it up and share the things learned while implementing it.
There are a couple of terms to be familiar with to be able to understand how Kafka works.
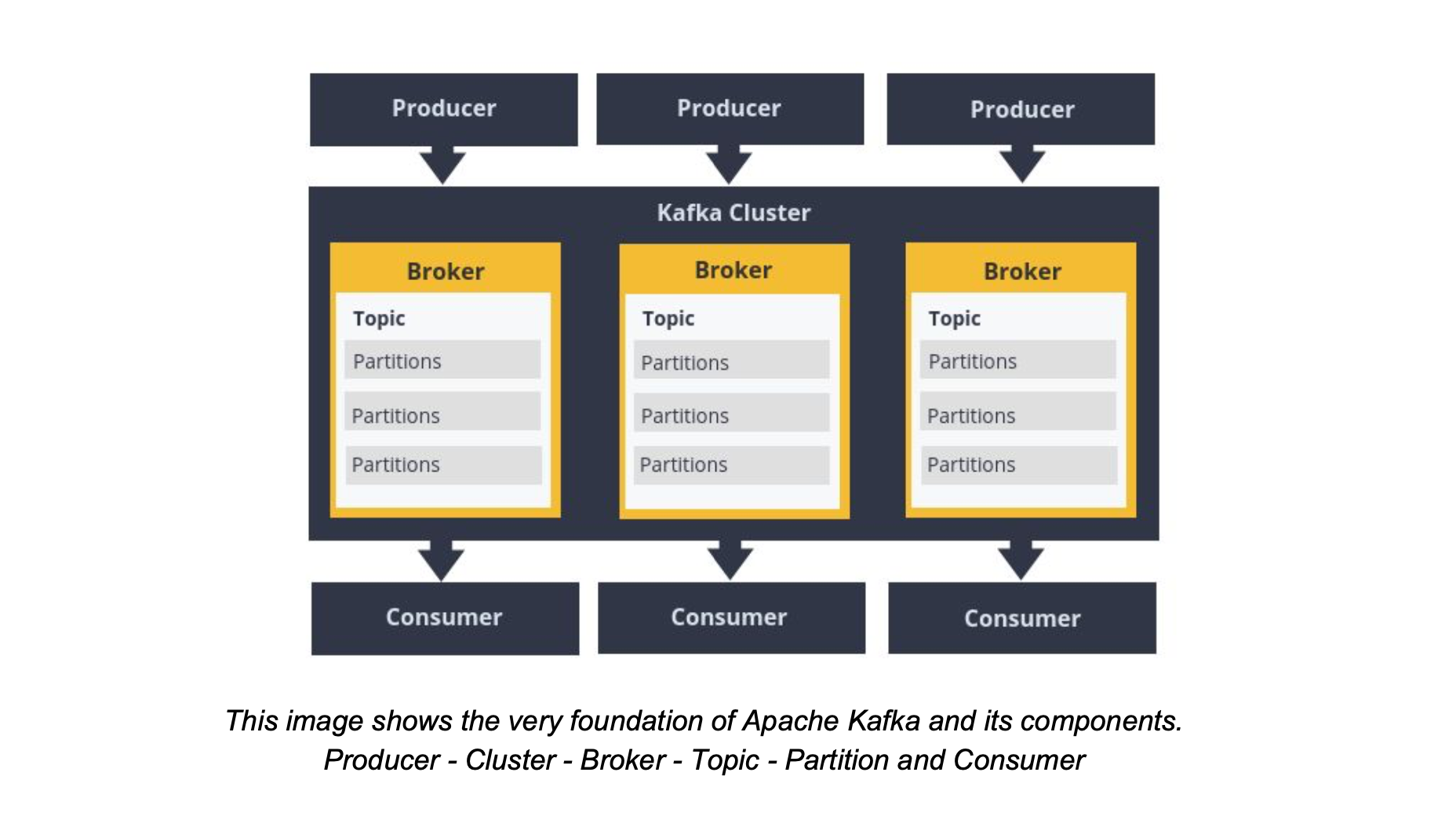
Cluster: A cluster in Kafka is a collection of one or more brokers or nodes.
Broker: A broker is a single Kafka instance and it like a mediator between the producer and the consumer. The producer pushes records(events) to a topic within a Kafka broker.
Topic: A topic in Kafka is a way of grouping and categorizing records(events) together. A single broker can contain one or more topics that groups together one or more partitions(logs of events).
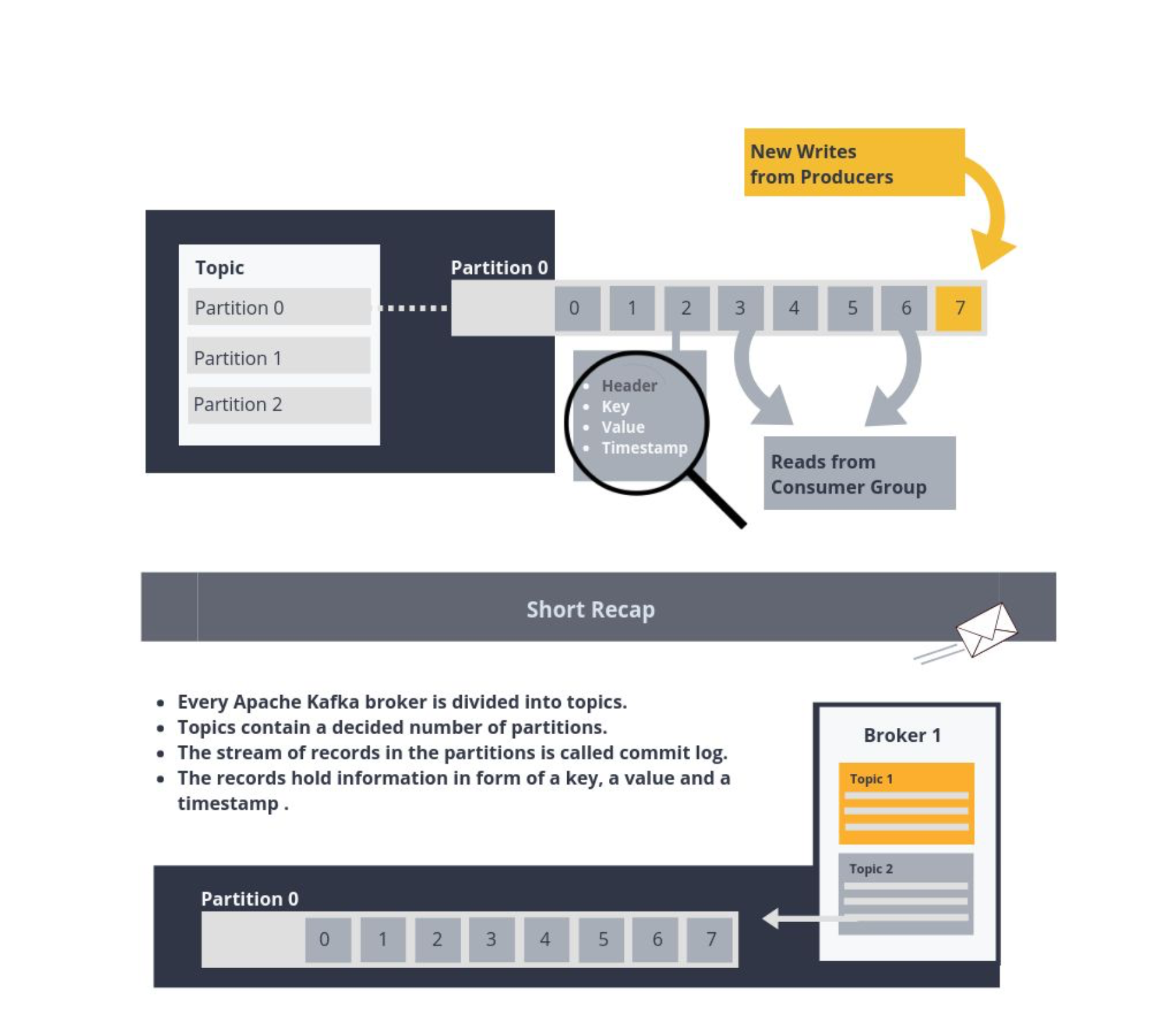
A partition: A partition in Kafka is basically a log. These logs are actually streams of records or events happening in real-time. Each new event or record is usually appended to the end of the log. A record usually contains a key, value, timestamp, header, metadata. The headers and metadata are optional fields. Also, records in partitions are also replicated across brokers. This provides redundancy of messages in the partition, such that another broker can take over leadership if there is a broker failure
Offset: An offset in Kafka is an integer that is used to track the records that have been read by the consumer in a partition. This prevents the consumer from reading the same message multiple times.
Consumer: Consumers read messages. In other publish/subscribe systems, these clients may be called subscribers or readers. The consumer subscribes to one or more topics and reads the messages in the order in which they were produced. The consumer keeps track of which messages it has already consumed by keeping track of the offset of messages
Producer: Producers create new messages. In other publish/subscribe systems, these may be called publishers or writers. In general, a message will be produced on a specific topic.
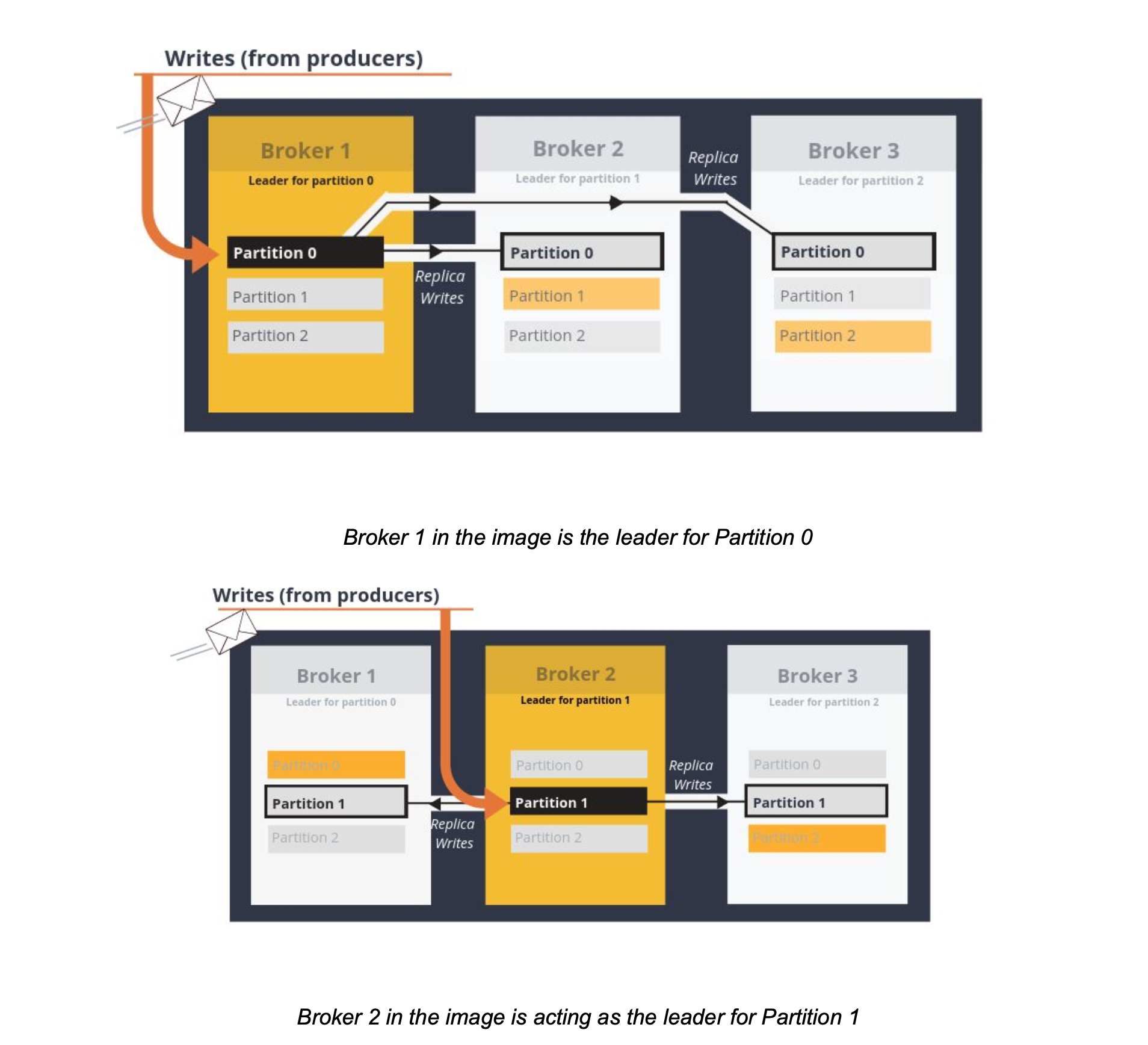
Partition Leader: This is the leader that controls the read-and-writes for the partition. A partition leader is elected by Zookeeper and while other partitions become followers, The partition followers replicate data across brokers. When one partition leader goes down, a partition follower in another broker is automatically elected leader. This feature makes Kafka fault-tolerant. The leader appends the records to its commit log and increments its record offset. Kafka then exposes the record to the consumer(s) after it has been received and committed.
Zookeeper: ZooKeeper is used for managing and coordinating Kafka broker. ZooKeeper service is mainly used to notify producer and consumer about the presence of any new broker in the Kafka system or failure of the broker in the Kafka system.
Consumer Group: A consumer group includes the set of consumers that are subscribing to a specific topic. Kafka consumers are usually a part of a consumer group. Each consumer in the group is assigned a set of partitions, from which they are able to consume messages. Each consumer in the group will receive records from different subsets of the partitions in the topic.
Rebalancing: Given a consumer group that contains a set of consumers, when a new consumer joins the new group, the consumers will attempt to "rebalance" the load to assign partitions to each consumer
Benefits of using Kafka
Fault-Tolerant: Records in partitions are replicated between brokers, this feature is what makes Kafka resilient and fault-tolerant. It can still continue functioning when a broker goes down in the cluster
Scalability: Kafka is a distributed system, which is able to be scaled quickly and easily without incurring any downtime. Apache Kafka is able to handle many terabytes of data without incurring much at all in the way of overhead.
Multiple Consumers: Multiple consumers can subscribe to the same topic because Kafka allows the same message to be replayed for a given window of time.
Low Latency: Apache Kafka offers low latency value, i.e., up to 10 milliseconds. It is because it decouples the message which lets the consumer consume that message anytime.
High Throughput: Due to low latency, Kafka is able to handle more number of messages of high volume and high velocity. Kafka can support thousands of messages in a second. Many companies such as Uber use Kafka to load a high volume of data.
** Reduces the need for multiple integrations**: Essentially, Apache Kafka reduces the need for multiple integrations–as all your data goes through Apache Kafka. Rather than your developers coding multiple integrations so you can harvest data from different systems, you only have to create one integration with Apache Kafka for each producing system and each consuming system.
There are many things that can be done with Kafka on an enterprise level. To learn more about Kafka and how to set up a broker, You can check this https://kafka.js.org/