- Published on
How to Get Started with Apache Flink for Effective Stream Processing
- Authors

- Name
- tomiwa
- @sannimichaelse
Introduction
In big data, the ability to process and analyze data in real-time has become imperative for organizations aiming to stay competitive. Stream processing, a paradigm that enables continuous and real-time data processing as it flows through a system, has gained prominence. This comprehensive guide navigates the intricacies of Apache Flink, a robust open-source stream processing framework while introducing GlassFlow as a streamlined alternative designed for smaller teams.
Understanding Stream Processing Concepts
Traditionally, data processing occurred in batches, involving the collection and analysis of data in fixed intervals. Stream processing, in contrast, deals with data as it occurs, providing real-time insights and quicker decision-making capabilities.
Key Concepts in Stream Processing
Event Time: Understanding the timestamp associated with events is crucial for accurate analysis, especially when events arrive out of order.
Watermarks: Watermarks help track progress in event time and ensure the system processes events within a defined timeframe.
Stateful Processing: Maintaining and updating state dynamically is fundamental for complex event processing and maintaining context over time.
Apache Flink Architecture
Overview of Apache Flink Architecture
Apache Flink's architecture centers on two primary components: the JobManager and TaskManagers. The JobManager orchestrates job execution, while TaskManagers handle specific tasks. The JobGraph illustrates the directed acyclic graph (DAG) of a Flink program, outlining data flow and transformations. Essential for fault tolerance, Checkpoints capture consistent snapshots of the distributed state, managed by the State Backend.
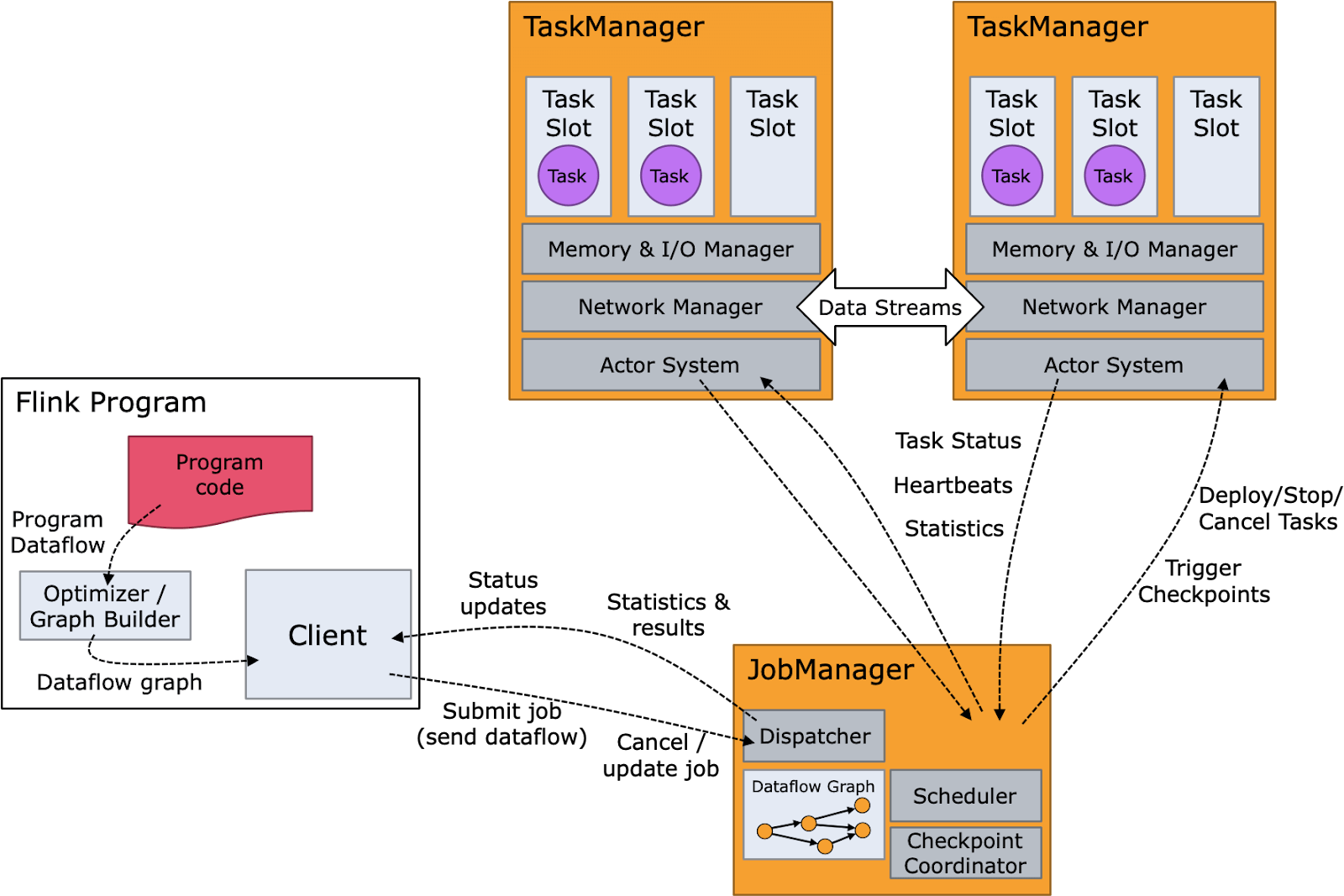
Apache Flink Components
1. JobManager:
Responsibility: Manages the execution of jobs.
Functionality: Accepts jobs, schedules tasks, and coordinates communication among TaskManagers.
2. TaskManagers:
Responsibility: Execute tasks assigned by the JobManager.
Functionality: Perform data processing, manage state, and communicate with other TaskManagers.
3. JobGraph:
Responsibility: Represents the directed acyclic graph (DAG) of a Flink program.
Functionality: Describes the data flow and transformations in the program.
4. Checkpoints:
Responsibility: Ensure fault tolerance by creating consistent snapshots of the distributed state.
Functionality: Enables recovery in case of node failures.
5. State Backend:
Responsibility: Manages the storage and retrieval of state.
Functionality: Allows pluggable backends (e.g., in-memory, file system, or distributed storage) to suit different use cases.
Apache Flink API's
DataStreams and DataSets:
Responsibility: Core APIs for stream and batch processing, respectively.
Functionality: Enable developers to express complex data processing pipelines, with DataStreams as a critical focus for stream processing.
Developing Your First Flink Application
Understanding Event Time Processing
Event Time Processing in Apache Flink focuses on events' actual occurrence time, addressing challenges posed by out-of-order arrivals. Unlike traditional processing, which relies on arrival time, Flink assigns timestamps based on event occurrence, ensuring accurate temporal sequencing. Key to this is understanding watermarks, indicating time progress in the stream. Watermarks assist Flink in tracking event-time completeness and handling late-arriving events appropriately. Developers leverage windowing techniques for efficient analysis by grouping events within specific time intervals.
Exploring State Management in Flink
State in stream processing: Maintaining the state across a continuous stream is crucial in real-time data processing. Flink's state concept includes information like aggregations or counters, evolving with the data stream.
Fault Tolerance and Resilience: Flink excels in fault tolerance through periodic checkpoints, capturing the application's state. In failures, Flink seamlessly resumes computations from a consistent state, ensuring data processing reliability.
Seamless recovery: Flink's state management boasts a seamless recovery mechanism, restarting from the last checkpoint in hardware failures or application errors. This prevents data loss, maintaining computation integrity
Developer-friendly APIs: Flink simplifies state management with accessible and intuitive APIs. Developers leverage key-value or broadcast state, offering flexibility for tailored solutions across diverse use cases
Leveraging Windowing and Time-based Operations in Flink
In Apache Flink, exploring Windowing capabilities enhances data analysis efficiency.
Understanding Windowing
Flink's Windowing allows developers to manage and analyze data within defined time frames. Instead of processing the entire data stream as one entity, windowing divides it into manageable sections or "windows," enabling focused analysis.
Temporal Organization for Analysis
By leveraging windowing, developers organize events based on occurrence time within specific intervals. This enhances data analysis precision, facilitating computations on a granular level. Windowing supports various types, including sliding and tumbling windows, ensuring flexibility in capturing temporal relationships.
Key Considerations for Windowing
Defining Windows: Developers can define Windows based on event counts or time durations, tailoring strategies to specific application requirements.
Overlap and Sliding Windows: Flink supports various window types, including sliding windows that enable data overlap across consecutive windows, enhancing flexibility in capturing temporal relationships.
Event Time Processing in Windows: Integrating windowing with Event Time Processing ensures accurate analysis by organizing events based on their actual occurrence time.
Deploying and Monitoring Flink Applications
Deployment Options: Navigating Flink's Environments
Standalone Mode: Flink's Standalone Mode is ideal for local development and testing, providing a controlled environment for developers to experiment with their applications. This mode facilitates a seamless and straightforward testing process before deploying applications to more complex environments.
Cluster Deployment: Understanding how to deploy Flink in a distributed cluster is paramount for production-ready applications. Cluster Deployment optimizes Flink's capabilities, leveraging distributed resources for scalability and reliability. This deployment option ensures applications can handle real-world data volumes and processing requirements.
Monitoring Flink Applications: Insight into System Health and Performance
Integrating with Monitoring Tools: Flink simplifies monitoring by seamlessly integrating with tools like Apache Flink Metrics. This integration enables developers to gain valuable insights into the health and performance of their systems. Monitoring tools contribute to proactive issue identification and effective resource management.
Performance Metrics and Analysis: Exploring key performance metrics is essential for optimizing Flink applications. Developers can conduct in-depth analyses by delving into metrics such as throughput, latency, and resource utilization. This exploration ensures applications are fine-tuned for efficiency and scalability, enhancing their performance in dynamic environments.
Integrating Flink with External Systems
Overview of message brokers
Integrating Apache Flink with external systems is vital for comprehensive data workflows in stream processing. Two prominent players in this integration are Apache Kafka and Apache Pulsar.
Apache Kafka:
A cornerstone in distributed streaming platforms.
Seamlessly integrates with Apache Flink.
Facilitates robust real-time data exchange, tapping into Kafka's scalable and fault-tolerant architecture.
Apache Pulsar:
Unique architecture with distinct advantages.
Essential to understand configuration intricacies for seamless integration.
Ensures a harmonious coexistence, unlocking potential for resilient and high-throughput data processing.
Configuring connections for Seamless Integration
Mastering connector configurations is crucial for a smooth data flow between Apache Flink and message brokers, such as Kafka or Pulsar. Setting up connectors ensures seamless data traversal, forming the backbone of efficient data processing pipelines.
Best Practices for interfacing Flink with external systems
Optimize Configurations for Performance:
Tailor Flink configurations for optimal performance.
Adjust parameters like parallelism, buffer sizes, and checkpoint intervals based on specific use cases and external system characteristics.
Handle Fault Tolerance Effectively:
Leverage Flink's fault-tolerance mechanisms, including checkpoints and stateful processing.
Configure checkpointing for efficient recovery in the event of failures.
Secure Communication Channels:
Prioritize certain communication channels.
Implement encryption and authentication mechanisms to safeguard sensitive data and prevent unauthorized access.
Batching and Buffering Strategies:
Implement effective batching and buffering strategies to optimize data transfers.
Adjust batch sizes and buffering mechanisms based on the characteristics of external systems.
Documentation and Versioning:
Maintain comprehensive documentation for integration setup, configurations, and considerations.
Implement versioning practices for Flink and external system components, ensuring smooth upgrades without disruptions.
Apache Flink in the Data Processing Pipeline
While Apache Flink excels in stream processing, it plays a specific role within the broader data processing pipeline. It's crucial to recognize that Flink is just one component, showcasing its strength when seamlessly integrated with other elements in a comprehensive data architecture.
Another challenge is the added complexity when integrating message brokers with Flink. The need for a message broker layer introduces intricacies in configuration and management, requiring careful coordination for smooth communication between Flink and these brokers. While message brokers enhance data processing capabilities, configuring them adds an extra management layer.
Additionally, the extra infrastructure setup requirement adds to Apache Flink's considerations. Establishing and maintaining the necessary infrastructure, especially with message brokers, can be demanding regarding resources and time. The complexities of configuring and managing these additional components highlight a potential trade-off between the advanced functionality of Apache Flink and the associated overhead. A thorough evaluation of these limitations is crucial for organizations looking to seamlessly integrate Apache Flink into their data processing workflows while optimizing its benefits.
GlassFlow: A Streamlined Alternative
GlassFlow is a compelling alternative in the stream processing landscape. With its emphasis on a lightweight and user-friendly design, GlassFlow provides a streamlined solution for organizations seeking efficiency in their data processing workflows. The development philosophy of GlassFlow revolves around simplicity and ease of use, ensuring that developers can swiftly adapt to its capabilities.
GlassFlow's advantages are noteworthy, covering 80% of everyday use cases despite its simplicity. Perhaps most appealing is the ability for teams to bypass the complexities of infrastructure setup, allowing them to dedicate more time and resources to direct application development. Tailored for smaller teams, GlassFlow fosters a developer-friendly environment, facilitating a quick and efficient development cycle.
Deciding between GlassFlow and Apache Flink involves assessing use case suitability, considering the robustness of Apache Flink for specific projects. Understanding resource requirements gives insights into scalability, and evaluating ease of integration is crucial for a smooth adoption process. The choice between GlassFlow and Apache Flink depends on the project's needs, resource constraints, and integration requirements. GlassFlow positions itself as a practical and efficient alternative, providing a tailored solution for streamlined stream processing. If you wish to explore further insights into streaming pipelines, I suggest taking a look at the blog on GlassFlow.
Conclusion
Apache Flink is a powerful and versatile stream processing framework, boasting robust capabilities that make it a go-to choice for diverse applications. However, for smaller teams seeking a lightweight and efficient solution, GlassFlow presents a compelling alternative. The decision between Apache Flink and GlassFlow hinges on carefully considering the specific requirements of your project and the size of your team. As we look ahead, exploring potential trends in the ever-evolving field of stream processing is essential, ensuring that your chosen solution aligns with the dynamic landscape of data processing advancements.